8GPU: HPCDIY-ERMGPU8R4S に RTX3090を8枚実装してGPU100%での消費電力と温度
HPCDIY-ERMGPU8R4S(こちら)にGeForce RTX 3090 を8枚実装し、gpu_burn(こちら)を実行して、消費電力と温度が定常状態になるまでを nvidia-smi -l で監視してみました。
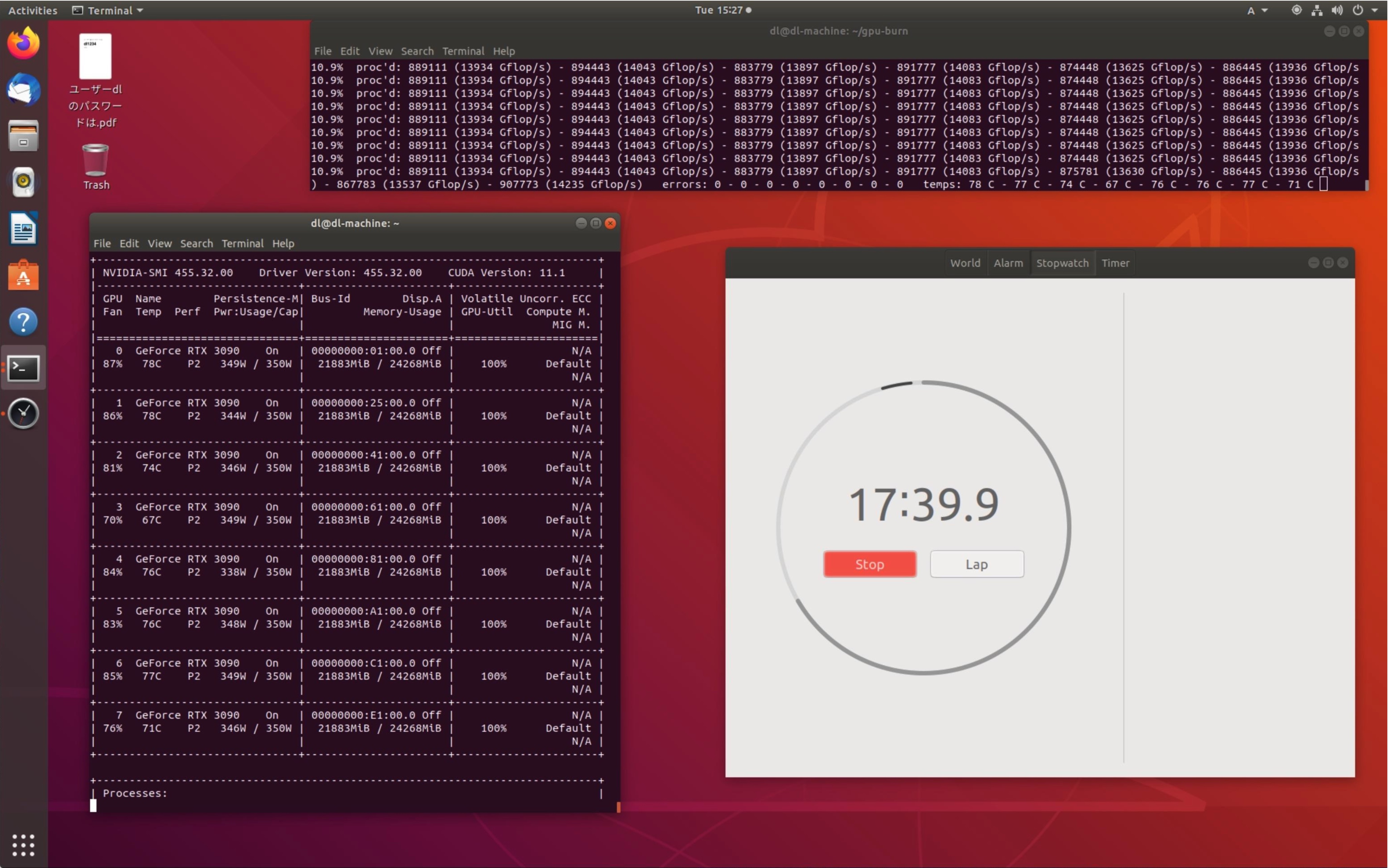
HPCDIY-ERMGPU8R4S(こちら)にGeForce RTX 3090 を8枚実装し、gpu_burn(こちら)を実行して、消費電力と温度が定常状態になるまでを nvidia-smi -l で監視してみました。
消費電力はそれぞれ約350W、温度はMAXで78°Cとまずまずの結果になりました。