RTX4090を4枚でgpu burnした時の消費電力とSmart Power
消費電力が最大級のgpu、RTX4090を4枚でgpu burnすると消費電力はどのくらいになるのかIPMIから確認してみました。 使用したマシンはSupermicroのSYS-741GE-TNRT、CPU: 2 * Intel Xeon Silver 4110T TDP 150W、Memory : 16 *...
消費電力が最大級のgpu、RTX4090を4枚でgpu burnすると消費電力はどのくらいになるのかIPMIから確認してみました。
使用したマシンはSupermicroのSYS-741GE-TNRT、CPU: 2 * Intel Xeon Silver 4110T TDP 150W、Memory : 16 * 32GB DDR5-4800 ECC RDIMM、SSD: 960GB M.2 PCIe Gen4 x4 NVMe M.2 SSDです。
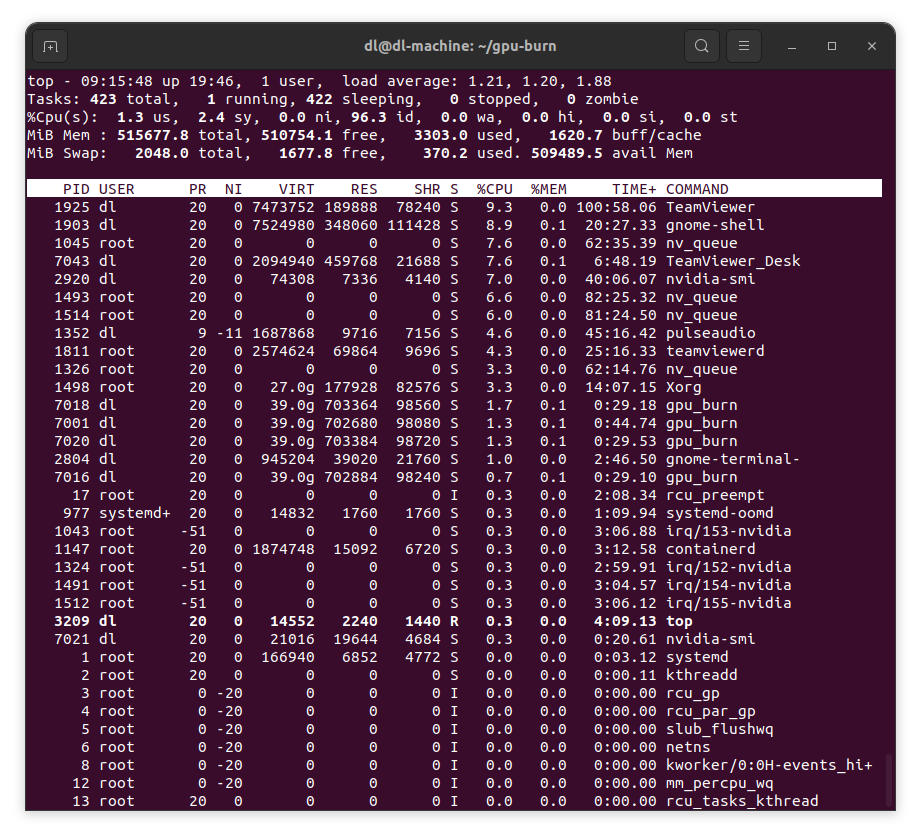
gpu_burnを実行してしばらくすると最初のscreenshotの状態で安定します。
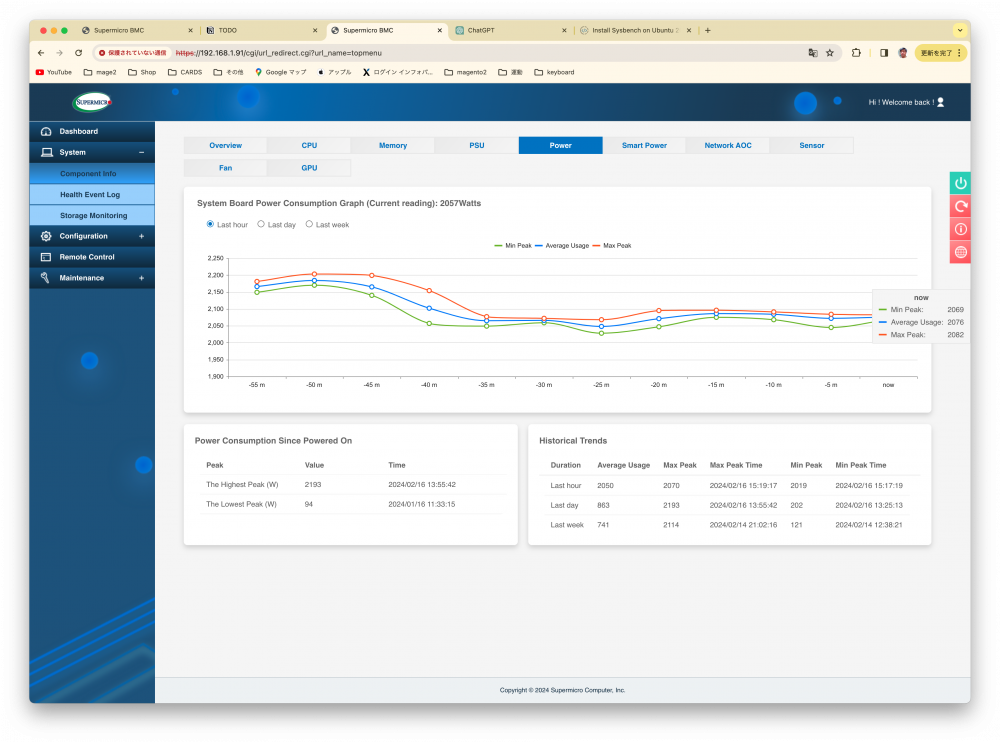
nvidia-smiで見ると4枚とも約450Wの消費電力になっています。IPMIから見ると約2080W消費していることがわかります。
topで見るとcpuはほとんど使われていません。
stress-ng --cpu 0 -t 10hを実行してcpuを100%使用も加えてみます。
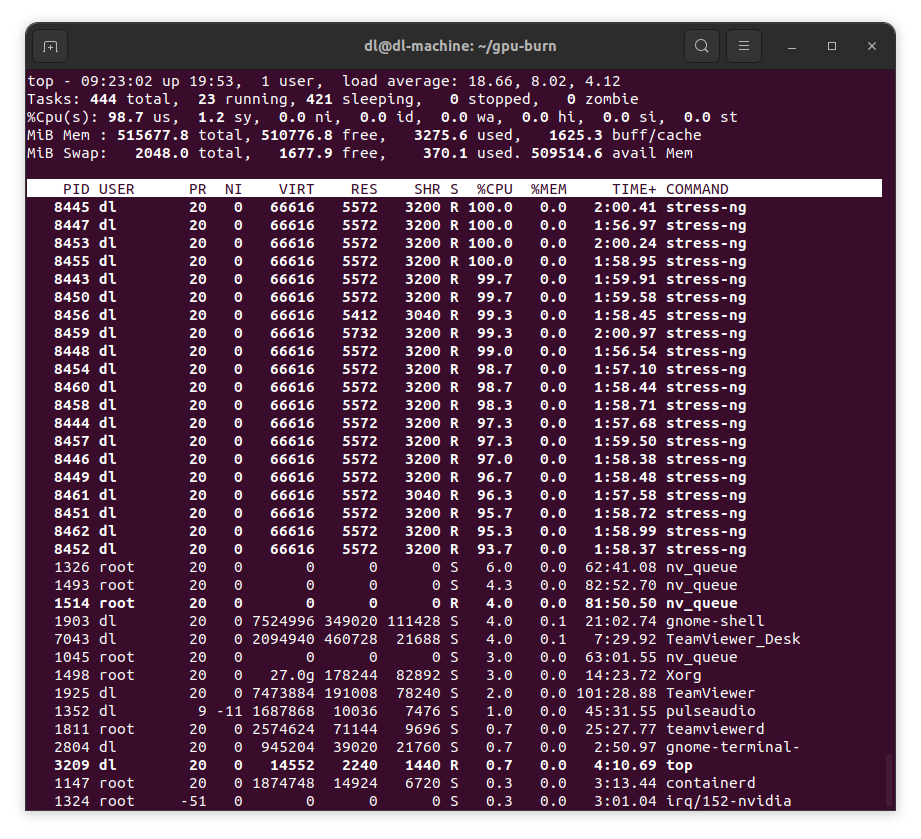
しばらくしてからIPMIで消費電力を確認すると約2160W消費していることがわかります。
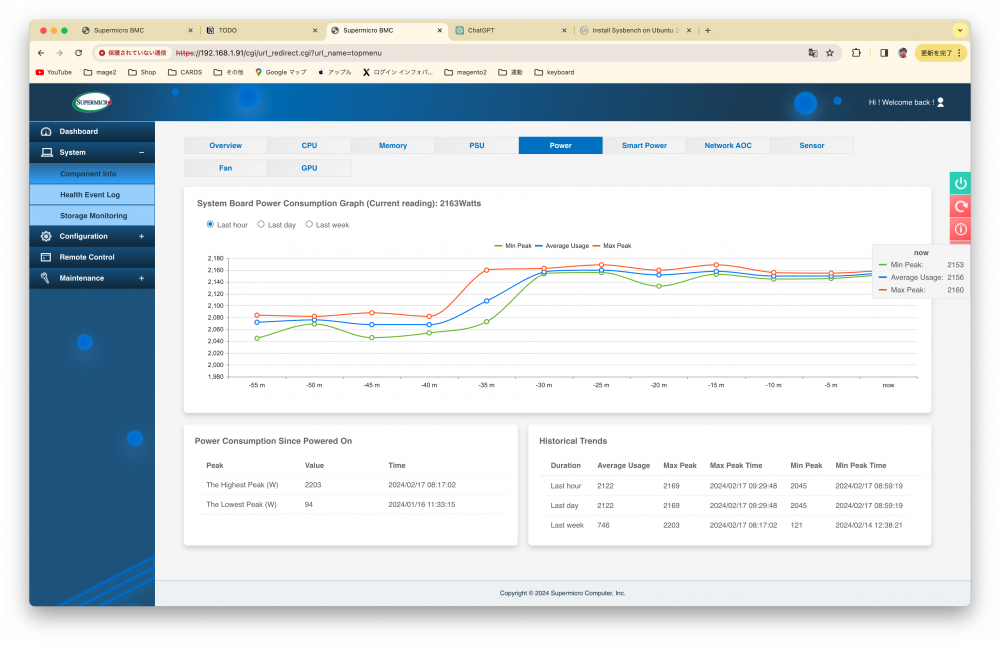
このマシンには、200V入力時に最大出力1800Wの電源ユニットが2つ搭載されています。前世代までのSupermicroのマシンでは消費電力が1800Wを超えると電源がshutdownされていました。
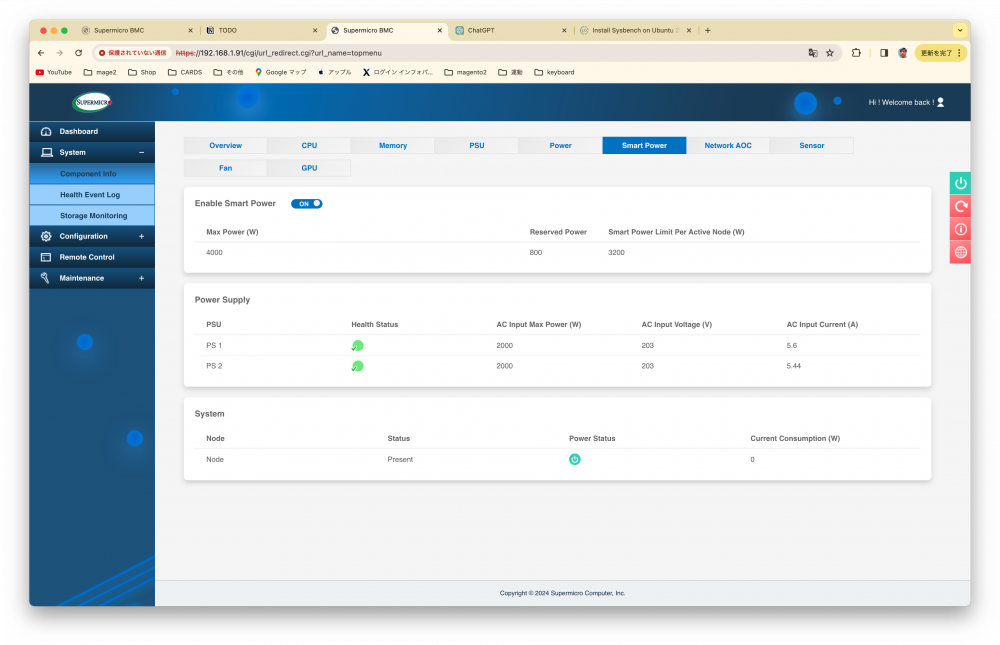
どうして2160Wも消費しているのに、問題なく動作し続けているのでしょうか。その理由は、新搭載されたSmart Powerという機能にあります。上の図を見るとPowerの右隣にSmart Powerというタブがあるのがわかります。そこをクリックすると下図が現れ、Smart Powerを有効(デフォルトで有効になっています)にすると、何と3200Wまで供給可能になることがわかります。この機能が存在するおかげで、前世代までの4gpu搭載可能機種では不可能なrtx4090が4gpuでの安定動作が可能になっています。