A100×4は必須ではなかった:DS4 q2をA100 80GB×2 NVLinkで動かす
DS4 q2-imatrix / ctx131K の短時間smokeと8K benchmarkが、A100 80GB×2 NVLink接続ペアで完走しました。今回の結果は q2・短時間検証・NVLink接続ペアという条件付きですが、少なくとも入口構成としてはA100×4必須ではない可能性を確認できました。
DS4 q2-imatrix / ctx131K の短時間smokeと8K benchmarkが、A100 80GB×2 NVLink接続ペアで完走しました。今回の結果は q2・短時間検証・NVLink接続ペアという条件付きですが、少なくとも入口構成としてはA100×4必須ではない可能性を確認できました。
Local LLM controller、Web検索、安全なCLI操作を組み合わせ、LLZOのLiイオン拡散評価に向けたQuantum ESPRESSO環境構築とbounded sanity runまでを実践しました。
RTX PRO 6000 Blackwell 2GPU評価機で、Qwen2.5-72B BF16/FP8/NVFP4、Nemotron3 120B FP8、Qwen3 235B NVFP4をQE/LAMMPS入力生成タスクで比較しました。
ローカルLLMはAllegro/NeQUIPの学習設定YAMLを作れるのか:Nemotronでmetadata-only preflightを検証 これは性能ベンチマークではありません。A100x4上のローカルLLMで、Allegro / NeQUIPの学習設定YAMLをどこまで安全に作り、実行前に確認できるかを調べた機能検証です。 結論から言うと、NemotronはAllegro / NeQUIPのtraining YAML候補を生成できました。既存SIF内で torch / nequip / allegro のimport、A100x4のCUDA可視
ローカルLLMはHPC入力ファイルを作り、エラーを直せるのか:NemotronでQuantum ESPRESSOとLAMMPSを検証 この記事の位置づけ これは性能ベンチマークではなく、 ローカルLLMがHPC入力ファイルの生成、実行ログを使った修正、再実行まで支援できるか を確認した機能検証です。 H200 NVLやRTX PRO 6000 Blackwellへの一般化はせず、次回以降の別フェーズとして扱います。 結論 A100 80GB x4上で NVIDIA-Nemotron-3-Nano-30B-A3B-BF16 をローカル配信し、Quantum
Server Gear Blog では、GPUサーバー、HPC、RescueReady OS、GPU Start Console、ローカルLLM、ベンチマーク検証などについて発信していきます。 手順書、証跡、runbook は notes.server-gear.com に集約し、このブログでは開発背景、考え方、検証記録、導入事例を中心に扱います。
FP64 synthetic だけでは見えない GPU 比較: QE と LAMMPS の確認結果 結論 A100 が最速 でした。今回の比較では、QE long-run と LAMMPS selected stable case の両方で最上位です。 Ada は実用域 でした。QE long-run と custom LLZO LAMMPS の selected stable case の両方で、A100に次ぐ現実的な選択肢です。 Blackwell は今回の条件と現行スタックでは Ada より遅い 結果でした。差の主因は収束回数増ではなく、 elec
DoMINOで“外部空力(CFD)”を秒オーダーで試す(初心者向け) 結論(1分) DoMINO(DoMINO-Automotive-Aero NIM)は、車体形状(STL)から 抗力/揚力 と 表面圧力分布 を返す「CFDサロゲート(代理モデル)」です。 4GPUマシンでは、 同時リクエスト(並列) を増やすことでスループットがほぼ比例して伸びます。 実測では、H100 NVL 4GPUで conc=1→9.16 req/min、conc=4→36.92 req/min(約4倍)、conc=8→55.49 req/min でした。 --- 1) DoM
オンプレLLMでログ一次切り分け:Llama 3.3 70Bでやってみた(根拠引用を強制) このページの狙い LLMに「障害の原因を当てさせる」よりも、 (1) ログから根拠を抜き出す → (2) 可能性を整理 → (3) 次に打つコマンドを提案 までを“オンプレで”完結させる例です。 --- 入力ログ(3行) 今回は、よくあるパターンの短いログ断片で試しました(抜粋)。 NVRM: Xid (PCI:0000:3b:00): 31, pid=1234, Ch 00000010, MMU Fault CUDA error: out of memory s
AI推論サービング実測:A100×4 vs H100 NVL×4(vLLM / Qwen2.5-7B)TTFTと同時ユーザー 結論(3行) 同時32の出力スループット: H100×4 = 5414 tok/s , A100×4 = 3723 tok/s ( 1.45× ) 同時32のTTFT(平均): H100×4 = 66.66 ms , A100×4 = 82.11 ms (H100の方が短い) つまり 「同時ユーザーが増えるほど差が効く」 =社内AI・RAG・運用支援のような“多人数同時利用”でGPU選定の根拠にしやすい --- これは何の実測?
GROMACS 溶媒和ΔGをGPUで回す:λ窓並列で意思決定を前倒し(A100実測→H200 NVLへ) 前提(ここが大事) このページの数値は A100 80GB×4 での実測です。 販売対象の H200 NVL(1/4/8GPU) でも同じ考え方で、 「λ窓(+replica/複数案件)を並列化して、壁時計を短縮」 できます。 H200 NVL向けには、お客様の系・条件に合わせて PoCで実測値を提示 します。 結論(先に要点) 同じΔGを再現 :A100とH100で溶媒和ΔGは誤差内で一致(計算として妥当) A100→H100で壁時計短縮 :4GP
LLZO粒界のLi-rich仮説を“支持”できた。だからこそGPUで仮説検証を高速に回す価値がある 先に全体像を見たい方へ: LLZO Fast-charge bottleneck map に、bulk / grain boundary / interface をまたいだ比較と、現時点での canonical な fixed stack をまとめています。 結論だけ先に :今回の検証は、 「LLZOの粒界(GB)がLi-richになりやすい」傾向は“見えた(仮説を支持する方向)” (Li濃度ピーク比 ≈ 3.14× 、過剰面密度 Γ ≈ 15.0 #/n
notes-migration
Research Note Ep0: LLZO + Li + ML-IAP + Allegro このページは notes(MkDocs)版へ移行中です。 TL;DR LLZO短絡問題に対し、 QE × ML-IAP(Allegro/NequIP) × LAMMPS で「再現可能に回る」ワークフローを作る導入編です。 DeepMD系ワークフローを土台にしつつ、 E(3)等価 なモデル(Allegro)へ移行する理由と評価観点を整理します。 まずは 粒界(grain boundary)でのLi偏析・局在 を前駆現象として定量化し、後続で界面シナリオへ接続しま
notes-migration
H200 NVL: Li/LLZO DOS(Quantum ESPRESSO) このページは notes(MkDocs)版へ移行中です。 TL;DR QEで SCF/NSCF → DOS を回す手順を、H200 NVL 前提で「再現できる形」に整理します。 GPU計算では 環境差(ドライバ/CUDA/ライブラリ) が効きやすいので、まずは最小の確認ポイントを押さえるのが近道です。 DOSは「計算が合っているか」の sanity check にも使えます(電子状態の差分が見える)。 このページで得られること QEでDOSを出す最小手順(何を揃えればOKか)
notes-migration
Ep2: QE GPU + Allegro training(H200 NVL) このページは notes(MkDocs)版へ移行中です。 TL;DR H200 NVL 環境で QE(DFT)をGPU実行 し、得られたデータで Allegro/NequIP を学習 する流れを「再現できる形」に整理します。 つまずきやすいのは 環境差(ドライバ/ライブラリ/ビルド条件) と データ整形(学習フォーマット) です。ここでは最小の確認ポイントをまとめます。 「学習の反復を速く回す」なら 8GPU、「まず運用を固めて回す」なら 4GPU が合いやすい(最終は要件
notes-migration
Ep1: LLZO/Li interface(DFT + ML-IAP + Allegro) このページは notes(MkDocs)版へ移行中です。 TL;DR LLZO/Li 界面を題材に、 QE(DFT)→ 学習データ → Allegro/NequIP 学習 → 推論/AI-MD へ繋ぐ「界面編」です。 つまずきやすいのは 界面モデルの作り方(構造の整合) と 学習データのバランス(界面/バルク/欠陥など) です。 まずは「小さく完走する」最小構成を作り、必要に応じてサンプル数・バリエーションを増やします。 このページで得られること 界面(inte
legacy-server-blog
LLZO短絡(デンドライト)を最短で理解するため、まず粒界でのLi偏析・拡散を定量化。Quantum ESPRESSOでDFTデータ生成→Allegro/NequIP学習→LAMMPS(Kokkos)で大規模AI‑MDをH200 NVL 4/8GPUで実行し、D/EaなどのKPIと回せる3Dで共有します。
notes-migration
H200 NVL: QE + DeepMD + LAMMPS(LLZO Li-ion path 3D) GPU計算で再現するLLZO 96原子 3×3×3 スーパーセル中のLi拡散経路 — Quantum ESPRESSO+DeepMD+LAMMPSによる3D可視化実測 — H200 NVL × QE / DeepMD / LAMMPS で、“DFT級の理解”を “MDスケールの現象”へ 追記(2025-12-13)|方針更新 最終ゴール(LLZO短絡/デンドライト問題にAI‑MDで迫る)は維持しつつ、まず LLZO粒界×Li偏析(前駆現象) を優先して
legacy-server-blog
RTX PRO 6000 Blackwell サーバーエディションなどの NVIDIA GPU で、nvidia-smi を使って Power Limit(電力上限)を確認・変更する手順を初心者にもわかりやすく解説。min/max の確認方法から単体GPU・複数GPUへの設定コマンドまで、コピペで使える具体例付きです。
legacy-server-blog
これまで300W級が主流だったGPUに対し、RTX PRO 6000 Blackwellサーバーエディション96GB 600Wの4GPUマシンでパワーリミットを300〜600Wに変更しながら、トークン性能・GPU電力・サーバー全体の消費電力・ファン回転数がどう変化するかを実測しました。
legacy-server-blog
ML-IAP(Allegro)ポテンシャルをLAMMPS(Kokkos)で実行し、LLZO/Li界面の大規模AI-MDを8GPUで高速スケーリング。Liイオン拡散経路を“回せる3D”で可視化し、次世代HPC材料解析の実力を示します。
legacy-server-blog
GPU最適化したQuantum ESPRESSOでLLZO/Li界面のジオメトリ最適化を実行。大量DFTデータ取得+Allegro対応学習準備をシンプルに紹介します。
legacy-server-blog
LLZO-Li界面におけるリチウムデンドライト成長を、AIポテンシャルDeepMD から ML-IAP(Allegro) への移行観点で解析。次世代AI-MDワークフローの出発点を掘り下げます。
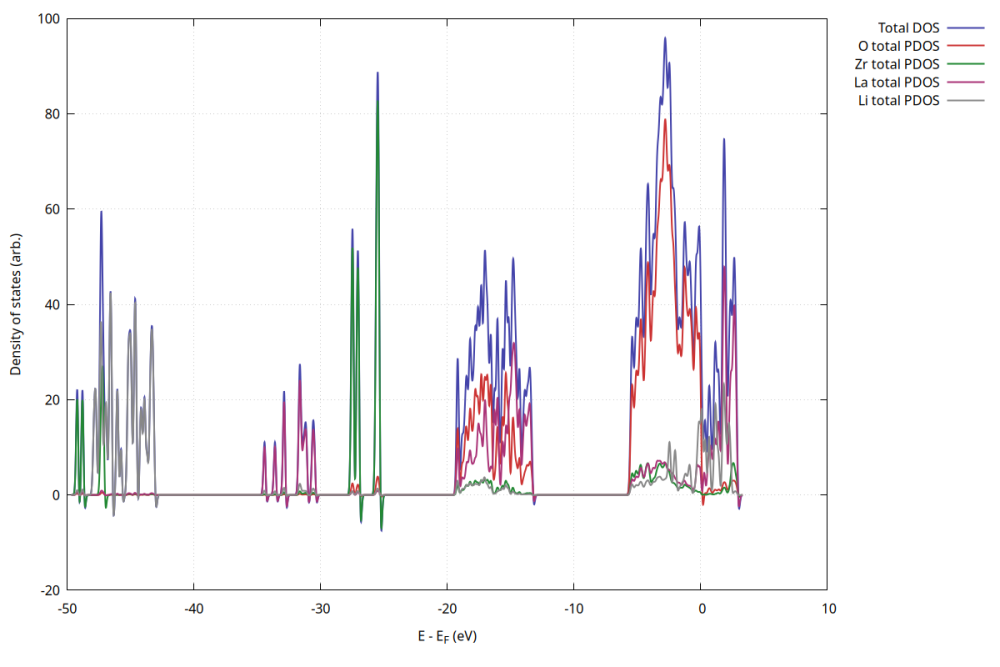
legacy-server-blog
LLZO/Li界面モデルを構築し、DOS・PDOS解析を通じて電子構造の特徴を抽出。ML-IAP(Allegro)への学習データ準備として優れた材料科学ワークフローを紹介します。